Operating Kafka at scale with Strimzi
Date: 2025-01-19
The source code for this lab exercise is available on GitHub.
Apache Kafka (Kafka) is an open source event streaming platform governed by the vendor-neutral Apache Software Foundation. It is optimized for processing vast amounts of data in real time, focused on availability, reliability and scalability. At the heart of Kafka is the publish-subscribe (pub/sub) model, topics and messages, with producers writing (producing) messages to one or more topics and consumers reading (consuming) messages from one or more topics.
Kafka can be flexibly deployed to a wide variety of environments and is also available as a managed service by cloud service providers, e.g.:
- Deploying on VM / bare metal directly from upstream releases
- Deploying as containers on a single host with Docker Compose V2
- Deploying to Kubernetes with Strimzi
- Available as a managed service by cloud service providers such as Amazon MSK or Confluent for Kafka
Deploying on VM / bare metal requires extensive manual operation for deployment, scaling and upgrades and is difficult to manage at scale so it is not covered in this article. Leveraging a managed Kafka service alleviates the operational burden from Kafka users and developers but may introduce vendor-specific features and optimizations leading to vendor lock-in. Therefore, we’ll start with a reproducible deployment of Kafka on a single host with Docker Compose V2, then move forward to deploying Kafka on Kubernetes with Strimzi in the second half of the article and appreciate the automated deployment and lifecycle management of Kafka clusters it delivers. In a sense, Kafka on Kubernetes with Strimzi gives the best of both worlds - you get an experience similar to managed Kafka services but with the added benefits of being vendor-neutral and retaining control over your data.
Before we start, let’s take a quick overview of Kafka’s architecture.
Kafka architecture
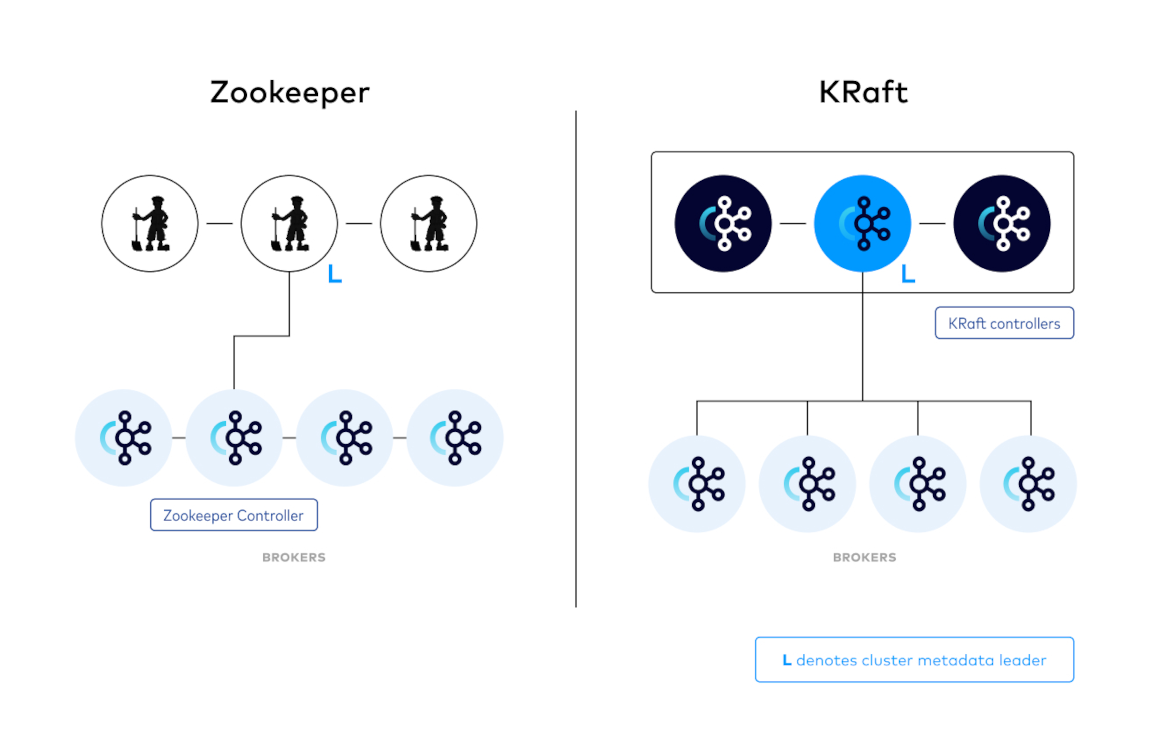
Source: KRaft: Apache Kafka Without Zookeeper
Kafka clusters consist of controllers and brokers as illustrated by the diagram to the right. Controllers store Kafka metadata and manage the entire cluster, while brokers store messages in topic partitions and process write requests from producers as well as read requests from consumers. Kafka controllers are analogous to Kubernetes control plane nodes and brokers are analogous to worker nodes.
In the legacy Kafka architecture illustrated by the diagram to the left, Kafka clusters store their metadata in Apache Zookeeper and assign a Kafka broker as Zookeeper controller for interacting with Zookeeper. This configuration is deprecated and Zookeeper support will be removed in the upcoming 4.0 release.
Lab: Deploy Kafka to Docker and Kubernetes
This lab has been tested with Kubernetes v1.32 (Penelope).
Prerequisites
Familiarity with Linux and Kubernetes is assumed. Otherwise, check out the courses below for a quick introduction or refresher.
Setting up your environment
A Linux environment with at least 2 vCPUs, 8GiB memory and sufficient available disk space capable of running Docker. This can be your own desktop/laptop if you’re a Linux user (like I am ;-), or a spare board (e.g. Raspberry Pi), physical server, virtual machine or cloud instance.
The reference environment is Ubuntu 24.04 LTS (Noble Numbat) so if you’re on a different Linux distribution, adapt apt-related commands with dnf / pacman / something else accordingly when installing system packages. Otherwise, the remaining instructions should be broadly applicable to most Linux distributions.
Install Docker and Docker Compose V2
We’ll use Docker for 2 purposes:
- In the first half of the lab, we’ll use Docker with Docker Compose V2 to spin up a Kafka cluster manually with 1 controller and 1 broker
- In the second half of the lab, we’ll use Docker to spin up a kind Kubernetes cluster and use it to spin up Kafka clusters automatically with the Strimzi operator
Install Docker and Docker Compose V2, then add the current user to the docker group:
sudo apt update
sudo apt install -y docker.io docker-compose-v2
sudo usermod -aG docker "${USER}"
Log out and in for the changes to take effect.
Check that we have the correct version of Docker installed:
docker version
Sample output:
Client:
Version: 26.1.3
API version: 1.45
Go version: go1.22.2
Git commit: 26.1.3-0ubuntu1~24.04.1
Built: Mon Oct 14 14:29:26 2024
OS/Arch: linux/amd64
Context: default
Server:
Engine:
Version: 26.1.3
API version: 1.45 (minimum version 1.24)
Go version: go1.22.2
Git commit: 26.1.3-0ubuntu1~24.04.1
Built: Mon Oct 14 14:29:26 2024
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.7.12
GitCommit:
runc:
Version: 1.1.12-0ubuntu3.1
GitCommit:
docker-init:
Version: 0.19.0
GitCommit:
Check that the Docker Compose V2 plugin is installed:
docker compose version
Sample output:
Docker Compose version 2.27.1+ds1-0ubuntu1~24.04.1
Install kind, kubectl and Helm for Kubernetes
Now install kind, kubectl and Helm for Kubernetes. To install kind, simply follow the instructions in their Quickstart:
# For AMD64 / x86_64
[ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.26.0/kind-linux-amd64
# For ARM64
[ $(uname -m) = aarch64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.26.0/kind-linux-arm64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
Check the correct kind version is installed:
kind version
Sample output:
kind v0.26.0 go1.23.4 linux/amd64
For kubectl, the official instructions will suffice:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/.
Check that kubectl is correctly installed:
kubectl version --client
Sample output:
Client Version: v1.32.0
Kustomize Version: v5.5.0
For command-line completion, add the following line to your ~/.bashrc:
source <(kubectl completion bash)
Now save the file and run:
source ~/.bashrc
Likewise, install Helm with the commands below:
wget https://get.helm.sh/helm-v3.16.4-linux-amd64.tar.gz
tar xvf helm-v3.16.4-linux-amd64.tar.gz
sudo mv linux-amd64/helm /usr/local/bin/helm
Check the Helm version:
helm version
Sample output:
version.BuildInfo{Version:"v3.16.4", GitCommit:"7877b45b63f95635153b29a42c0c2f4273ec45ca", GitTreeState:"clean", GoVersion:"go1.22.7"}
Add the following line to your ~/.bashrc for command-line completion:
source <(helm completion bash)
Now save the file and run:
source ~/.bashrc
Install cloud-provider-kind for load balancing
kubernetes-sigs/cloud-provider-kind provides load-balancing capabilities for kind Kubernetes clusters, by automatically spinning up an Envoy proxy container for each LoadBalancer service. The LoadBalancer service is accessible only from the Docker host by default. Specify the -enable-lb-port-mapping option to expose LoadBalancer services externally, which opens a random high-numbered port on the Docker host for each port specified in the LoadBalancer service.
Download and install cloud-provider-kind:
wget https://github.com/kubernetes-sigs/cloud-provider-kind/releases/download/v0.5.0/cloud-provider-kind_0.5.0_linux_amd64.tar.gz
tar xvf cloud-provider-kind_0.5.0_linux_amd64.tar.gz
sudo mv cloud-provider-kind /usr/local/bin/cloud-provider-kind
An example systemd unit file cloud-provider-kind.service to start and manage cloud-provider-kind as a background daemon:
# /etc/systemd/system/cloud-provider-kind.service
[Unit]
Description=Cloud Provider Kind Service
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/cloud-provider-kind -enable-lb-port-mapping
Restart=on-failure
[Install]
WantedBy=multi-user.target
Install the unit file to /etc/systemd/system/cloud-provider-kind.service, then restart systemd, start the service and enable it to auto-start at system boot:
sudo systemctl daemon-reload
sudo systemctl enable --now cloud-provider-kind.service
Deploy Kafka to Docker with Docker Compose V2
Docker Compose V2 provides a convenient method of spinning up multiple related containers on a single Docker host using a compose.yaml configuration file. If you’re familiar with Kubernetes, understanding Docker Compose should be a breeze and requires no introduction ;-)
Clone the sample repository for this lab and make it your working directory: DonaldKellett/kafka-kraft-1c1b
git clone https://github.com/DonaldKellett/kafka-kraft-1c1b.git
pushd kafka-kraft-1c1b/
Take a moment to inspect compose.yaml and understand the configuration, then start the Kafka cluster with Compose:
docker compose up -d
Sample output:
[+] Running 3/3
✔ kafka-broker-0 Pulled 80.2s
✔ kafka-controller-0 Pulled 80.2s
✔ 69b14d9ee1f8 Pull complete 74.7s
[+] Running 3/3
✔ Network kafka-kraft-1c1b_app-tier Created 0.1s
✔ Container kafka-controller-0 St... 1.7s
✔ Container kafka-broker-0 Starte... 0.7s
Tip: the sample repo uses the bitnami/kafka image from Docker Hub.
Recall that Kafka messages are divided into topics. Producers write messages to a Kafka topic which can then be read by consumers from the same topic. Let’s create a new topic kafka-hello-world with the kafka-topics.sh script bundled with Kafka on our controller by connecting to our broker:
docker exec kafka-controller-0 \
/opt/bitnami/kafka/bin/kafka-topics.sh \
--bootstrap-server kafka-broker-0:9092 \
--create \
--topic kafka-hello-world
Sample output:
Created topic kafka-hello-world.
Now open a new terminal tab or window and run the kafka-console-consumer.sh script on our controller to start listening for messages in the kafka-hello-world topic. Keep the tab or window open and keep the script running - you should see no output for now.
docker exec -it kafka-controller-0 \
/opt/bitnami/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka-broker-0:9092 \
--topic kafka-hello-world \
--from-beginning
Return to your original terminal tab or window and run the kafka-console-producer.sh script on our controller to start writing messages to the kafka-hello-world topic. You should see an angular prompt > within a few seconds:
docker exec -it kafka-controller-0 \
/opt/bitnami/kafka/bin/kafka-console-producer.sh \
--bootstrap-server kafka-broker-0:9092 \
--topic kafka-hello-world
Write a few messages separated by newlines. For example:
>Hello World!
>This is my first Kafka cluster!
Now watch the messages appear in the consumer’s console. For example:
Hello World!
This is my first Kafka cluster!
Press Ctrl+C on both terminal tabs or windows when done. You should also the following output printed to the consumer’s console:
Processed a total of 2 messages
Shut down the Kafka cluster and remove the containers:
docker compose down
Sample output:
[+] Running 3/3
✔ Container kafka-broker-0 Remove... 1.3s
✔ Container kafka-controller-0 Re... 0.7s
✔ Network kafka-kraft-1c1b_app-tier Removed 0.2s
Before we move on to Kafka on Kubernetes with Strimzi, here are a few exercises to consider if you would like to learn more about Kafka and how it works:
- Fork the repository and clone it (your fork) again so your modifications can be saved and published to GitHub, or another Git forge of your choice
- What happens if we remove the dependency of the broker on the controller in
compose.yaml? Try starting and shutting down the Kafka cluster a few times - The Kafka cluster loses all its data in its current configuration when it is shut down. Modify the
compose.yamlfile to introduce persistence so Kafka retains its topics and messages when it is shut down and restarted. - Make the control plane highly available by modifying
compose.yamlto manually scale the number of controllers to 3. Why does Kafka require an odd number of controllers for high availability? - Make the data plane highly available by modifying
compose.yamlto manually scale the number of brokers to 3 or above. Why is 3 the minimum recommended number of brokers for high availability?
Clean up the repository as we won’t need it for our next section.
popd
rm -rf kafka-kraft-1c1b/
Deploy Kafka to Kubernetes with Strimzi
Strimzi is an operator for running Kafka clusters on Kubernetes. It automates the deployment and lifecycle management of Kafka clusters so users and developers do not have to worry about which environment variables to set on each Kafka server or manually migrating each node in legacy Kafka clusters with Zookeeper to the modern, native Kafka Raft (KRaft) architecture. Strimzi was originally developed by Red Hat and is now a CNCF Incubating project.
Prepare a private root CA
Let’s prepare a private root CA. This will come in handy later.
The openssl commands use to generate the certificates are explained in detail in my other blog post so they are presented without explanation here: Keycloak on Fedora Workstation with Podman | Fedora Magazine
Create our root CA certificate-key pair:
openssl req \
-x509 \
-new \
-nodes \
-keyout my-root-ca.key \
-sha256 \
-days 3650 \
-out my-root-ca.crt \
-subj '/CN=My root CA/DC=localhost'
Install the root CA certificate to /usr/local/share/ca-certificates/my-root-ca.crt and run update-ca-certificates:
sudo cp my-root-ca.crt /usr/local/share/ca-certificates/my-root-ca.crt
sudo update-ca-certificates
Start your Kubernetes cluster
With kind, your Kubernetes cluster is 1 command away.
kind create cluster
Install the Kubernetes Ingress NGINX controller
We’ll expose our Strimzi Kafka cluster with Ingress. Install the ingress-nginx controller with Helm and set it as default IngressClass. We’ll need to enable TLS passthrough as well for secure communication to our Strimzi Kafka clusters via Ingress since Kafka uses a custom binary protocol:
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm -n ingress-nginx install \
--create-namespace \
ingress-nginx \
ingress-nginx/ingress-nginx \
--version 4.12.0 \
--set controller.ingressClassResource.default=true \
--set controller.extraArgs.enable-ssl-passthrough=true
Get the IP of our ingress controller and prepare a TLS serving certificate
Get the LoadBalancer IP of our ingress controller with the command below:
kubectl -n ingress-nginx get svc \
ingress-nginx-controller \
-o jsonpath='{.status.loadBalancer.ingress.*.ip}'
Sample output:
172.18.0.3
Since the LoadBalancer IP is 172.18.0.3 in our case (yours might be different!), let’s create a TLS serving certificate for the IP address 172.18.0.3 and the following domains signed by our root CA:
strimzi-kafka.172.18.0.3.sslip.iostrimzi-kafka-broker-0.172.18.0.3.sslip.iostrimzi-kafka-broker-1.172.18.0.3.sslip.iostrimzi-kafka-broker-2.172.18.0.3.sslip.io
Remember to adapt the domain name and IP address based on the LoadBalancer IP address you got in the previous step.
openssl req \
-new \
-newkey rsa:2048 \
-nodes \
-keyout strimzi-kafka.key \
-sha256 \
-out strimzi-kafka.csr \
-subj '/CN=Strimzi Kafka/DC=localhost' \
-addext 'subjectAltName=DNS:strimzi-kafka.172.18.0.3.sslip.io,DNS:strimzi-kafka-broker-0.172.18.0.3.sslip.io,DNS:strimzi-kafka-broker-1.172.18.0.3.sslip.io,DNS:strimzi-kafka-broker-2.172.18.0.3.sslip.io,IP:172.18.0.3' \
-addext 'basicConstraints=critical,CA:FALSE' \
-addext 'keyUsage=digitalSignature,keyEncipherment' \
-addext 'extendedKeyUsage=serverAuth'
openssl x509 \
-req \
-days 365 \
-in strimzi-kafka.csr \
-CA my-root-ca.crt \
-CAkey my-root-ca.key \
-out strimzi-kafka.crt \
-set_serial 01 \
-sha256 \
-copy_extensions copy
Deploy the Strimzi operator with Helm
Let’s deploy the Strimzi operator with Helm and configure it to watch all namespaces. The Strimzi operator is responsible for managing Strimzi and Kafka related custom resources.
helm -n strimzi-kafka-operator install \
--create-namespace \
strimzi-kafka-operator \
oci://quay.io/strimzi-helm/strimzi-kafka-operator \
--version 0.45.0 \
--set watchAnyNamespace=true
Wait for the operator to become ready.
kubectl -n strimzi-kafka-operator wait \
--for=condition=Ready \
pods \
-l name=strimzi-cluster-operator \
--timeout=180s
Sample output:
pod/strimzi-cluster-operator-76b947897f-np8t2 condition met
Deploy a Strimzi Kafka cluster with 1 controller and 1 broker
Create a namespace strimzi-kafka for our Kafka cluster:
kubectl create ns strimzi-kafka
Now create a secret strimzi-kafka-cluster-tls containing the TLS serving certificate and key we generated earlier, to be used for accessing our Strimzi Kafka cluster over TLS ingress.
kubectl -n strimzi-kafka create secret tls \
strimzi-kafka-cluster-tls \
--cert=strimzi-kafka.crt \
--key=strimzi-kafka.key
Save the YAML manifests below as strimzi-kafka-1c1b.yaml. They include:
- A
KafkaNodePoolof 1 controller - A
KafkaNodePoolof 1 broker - A
Kafkacluster consisting of both node pools above
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: strimzi-kafka-controller-node-pool
namespace: strimzi-kafka
labels:
strimzi.io/cluster: strimzi-kafka-cluster
spec:
replicas: 1
roles:
- controller
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 1Gi
deleteClaim: true
kraftMetadata: shared
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaNodePool
metadata:
name: strimzi-kafka-broker-node-pool
namespace: strimzi-kafka
labels:
strimzi.io/cluster: strimzi-kafka-cluster
spec:
replicas: 1
roles:
- broker
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 1Gi
deleteClaim: true
kraftMetadata: shared
---
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: strimzi-kafka-cluster
namespace: strimzi-kafka
annotations:
strimzi.io/node-pools: enabled
strimzi.io/kraft: enabled
spec:
kafka:
version: 3.9.0
metadataVersion: "3.9"
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
- name: external
port: 9094
type: ingress
tls: true
authentication:
type: tls
configuration:
bootstrap:
host: strimzi-kafka.172.18.0.3.sslip.io
brokerCertChainAndKey:
certificate: tls.crt
key: tls.key
secretName: strimzi-kafka-cluster-tls
brokers:
- broker: 0
host: strimzi-kafka-broker-0.172.18.0.3.sslip.io
class: nginx
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
entityOperator:
topicOperator: {}
userOperator: {}
Remember to replace the DNS hostnames if your ingress controller LoadBalancer IP was different.
Apply the YAML manifests:
kubectl apply -f strimzi-kafka-1c1b.yaml
Wait for the strimzi-kafka-cluster Kafka cluster to become ready.
kubectl -n strimzi-kafka wait \
--for=condition=Ready \
--timeout=300s \
kafkas.kafka.strimzi.io \
strimzi-kafka-cluster
Sample output:
kafka.kafka.strimzi.io/strimzi-kafka-cluster condition met
The Kafka controller, broker and entity operator pods are running:
kubectl -n strimzi-kafka get pods
Sample output:
NAME READY STATUS RESTARTS AGE
strimzi-kafka-cluster-entity-operator-6b4bfc8c98-769fm 2/2 Running 0 11m
strimzi-kafka-cluster-strimzi-kafka-broker-node-pool-0 1/1 Running 0 12m
strimzi-kafka-cluster-strimzi-kafka-controller-node-pool-1 1/1 Running 0 12m
Observe that Ingress resources are created as well as per our Kafka configuration. This allows external clients to connect to our Strimzi Kafka cluster over TLS.
kubectl -n strimzi-kafka get ingress
Sample output:
NAME CLASS HOSTS ADDRESS PORTS AGE
strimzi-kafka-cluster-kafka-bootstrap nginx strimzi-kafka.172.18.0.3.sslip.io 172.18.0.3 80, 443 15m
strimzi-kafka-cluster-strimzi-kafka-broker-node-pool-0 nginx strimzi-kafka-broker-0.172.18.0.3.sslip.io 172.18.0.3 80, 443 15m
Here are a few open-ended exercises for the interested reader:
- How to connect to the Strimzi Kafka cluster securely from an external client via TLS? Is any additional configuration required?
- Try changing the authentication type from
tlstoscram-sha-512,oauthorcustom. What other configuration changes are required for each authentication type? Can you make it work? - Check out the topic operator, create and experiment with topics created via the
KafkaTopiccustom resource. What advantages doesKafkaTopicbring over manually creating and managing topics from an external client? - Check out some of the other custom resources provided by Strimzi as well. For example,
KafkaMirrorMaker2 - Modify the
KafkaNodePoolandKafkamanifests above to deploy a highly-available Strimzi Kafka cluster with 3 controllers and 3 brokers to a separate namespacestrimzi-kafka-ha. What changes are required for each custom resource, if any? Compare the changes to the Strimzi custom resources versus thecompose.yamlconfiguration file required to convert our Kafka clusters to an HA setup - Try an in-place scaling operation on our existing Strimzi Kafka cluster from 1 controller, 1 broker to 3 controllers, 3 brokers. Ensure that downtime and data loss is minimized. Is the scaling operation successful? How difficult (easy) is it with Strimzi? Is the entire process automated? How much (if any) manual intervention is required? What if we try the same in-place scaling operation on our Kafka cluster with Docker Compose?
Once you’re done experimenting, simply delete the cluster with a single command:
kind delete cluster
Concluding remarks and going further
Kafka is an open source event streaming platform optimized for real-time data processing. While it supports many deployment options, we saw in this lab how the Strimzi operator enables us to deploy and manage Kafka in an automated fashion much like a managed service but with the added benefit of being vendor-neutral and retaining control over your data. Furthermore, the abstractions provided by Strimzi in the form of custom resources simplify non-trivial configuration options such as TLS and OAuth authentication for Kafka administrators.
I hope you enjoyed this article and stay tuned for more updates ;-)
Subscribe:
![]()
![]()
![[Valid RSS]](/assets/images/valid-rss-rogers.png)
![[Valid Atom 1.0]](/assets/images/valid-atom.png)